OR
Auto synchronize Data from Production to Development using Script Daily
OR
Refresh data from Production to Development Server.
exec [sc].[cp_data_synch]
@p_SourceServerName = 'Source Server Name',
@p_SourceUserName = 'Source User Name',
@p_SourcePassword = 'Source Password',
@p_SourceDatabaseName = 'Source Database Name'
Batch File
Now, we will see how to create batch file which will execute above script.
Below is command which is used to execute above script.
SQLCMD -S [Server Name] -U [User Name] -P [Password] -Q "EXEC Asif.dbo.cp_data_synch"
You can get more details about SQLCMD from below link.
http://technet.microsoft.com/en-us/library/ms162773.aspx
Below are details of above parameters.
1. [Server Name] : You can get server name from you SQL Server Management Studio (SSMS) using below query
Query:
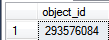
Select @@servername
2. [User Name] (Optional): If you want to connect SQL Server using SQL Authentication then you can define your user name here. Else it will connect using Windows authentication.
3. [Password] (Optional) : You can define SQL Server User Name Password here.
Scheduler
Now, we will see how to create windows "Task Scheduler" which will execute above batch file daily.
To do that, we need to follow below steps.
1. Go to Start -> Control Panel -> Administrative Tools -> Task Scheduler
2. Click on "Create Basic Task".

3. Enter Name and Description of Task and Click Next.

4. Choose appropriate schedule type and Click Next. I have choose "Daily".

5. Choose appropriate start time and recurring based on Schedule Type selected in last step. I have choose 9 AM for every day.

6. Choose action which you want to perform and Click Next. We have choose "Start a program" because we want to execute batch file for this task.

7. Browse batch file location from where you want to execute batch file for this task.

8. Below is task which is created in Windows Task Scheduler.

Auto synchronize Data from Production to Development using Script Daily
OR
Refresh data from Production to Development Server.
We mostly seen a situation where we want to synchronize data from Production to Development or QA Server on demand request, daily or weekly basis.
We have different tools to achieve it.
- Red Gate Data Synchronization
- Data Synchronize using SSDT
I come to a situation where my client doesn’t have a license software for SQL Server so we have installed express edition which doesn’t have SSDT installed with it.
In such situation, I thought to create dynamic procedure sc.cp_data_synch which will synchronize data from Production to Development Server based on table definition in Development Server.
Below are parameters for the procedure sc.cp_data_synch.
-
- Server Name of Production Server from where we want to synchronize data.
-
- User Name of Production Server.
-
- Password of Production Server
-
- Database Name of Production Server
Below is sample execution plan.
exec [sc].[cp_data_synch]
@p_SourceServerName = 'Source Server Name',
@p_SourceUserName = 'Source User Name',
@p_SourcePassword = 'Source Password',
@p_SourceDatabaseName = 'Source Database Name'
Batch File
Now, we will see how to create batch file which will execute above script.
Below is command which is used to execute above script.
SQLCMD -S [Server Name] -U [User Name] -P [Password] -Q "EXEC Asif.dbo.cp_data_synch"
You can get more details about SQLCMD from below link.
http://technet.microsoft.com/en-us/library/ms162773.aspx
Below are details of above parameters.
1. [Server Name] : You can get server name from you SQL Server Management Studio (SSMS) using below query
Query:
Select @@servername
2. [User Name] (Optional): If you want to connect SQL Server using SQL Authentication then you can define your user name here. Else it will connect using Windows authentication.
3. [Password] (Optional) : You can define SQL Server User Name Password here.
Scheduler
Now, we will see how to create windows "Task Scheduler" which will execute above batch file daily.
To do that, we need to follow below steps.
1. Go to Start -> Control Panel -> Administrative Tools -> Task Scheduler
2. Click on "Create Basic Task".
3. Enter Name and Description of Task and Click Next.
4. Choose appropriate schedule type and Click Next. I have choose "Daily".
5. Choose appropriate start time and recurring based on Schedule Type selected in last step. I have choose 9 AM for every day.
6. Choose action which you want to perform and Click Next. We have choose "Start a program" because we want to execute batch file for this task.
7. Browse batch file location from where you want to execute batch file for this task.
8. Below is task which is created in Windows Task Scheduler.
Below are scripts to download: